

AWSのLambdaで、JSON(もしくはJSONL)をCSVに変換する記事がなかったので書いてみた。
JSONL(JSONライン形式)で地味にハマっている人が多そうだ。。。
AWS(+python)に触れて一年未満の人が書いているので、間違い等あれば優しく教えて頂けると嬉しい。
想定している構成図
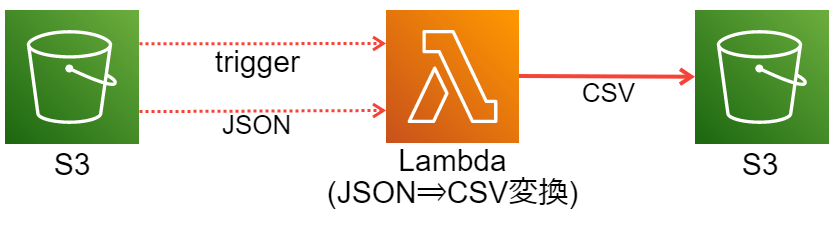
S3にJSONファイルがアップロードされたら、CSVファイルに変換してS3に置き直すイメージである。
分かりやすくするためにシンプルに記載したが、IoTCoreで収集したデータやKinesisDataFirehose(配信ストリーム)で収集したデータが入ってくる想定が多いかと思う。
実装編
大部分はこちらのサイトを参考にさせていただいた
今回のJSON⇒CSV変換のソースを作るにあたり、大部分は以下のQiitaを参考にさせて頂いた。
大変ありがとうございます。
Qiita 【Python】S3にアップロードされたCSVファイルをAWS LambdaでJSONファイルに変換する
などなどは、上記のQiitaを参考にして頂ければと思う。
そんなワケであまり深く考えずにS3トリガで実装してしまったが、EventBridgeの方がいいのかもしれない(EventBridgeで実装できるかは未検証)
EventBridgeでやる場合のトリガ方法はここに記載しない。また、Lambda引数の中身が変わってしまうため、後のソースコードはそのまま使えなくなる。各自読み替えて欲しい。
JSONの場合
ファイル形式
IoTCoreで収集したデータを直接収集して、S3に上げている人はこちらに該当する人が多いだろう。
こんな感じのデータである。
[
{"type":"device1","date":"2022/07/01 00:00:01","value1":100.001,"value2":29.509},
{"type":"device1","date":"2022/07/01 00:00:02","value1":105.002,"value2":30.001}
]上記データはキーなしだけど、キーありでもいけるんじゃないかな(適当)
Lambdaソース
import json
import csv
import boto3
import os
from datetime import datetime, timezone, timedelta
fieldnames = ['type', 'date', 'value1', 'value2'] # header情報
s3 = boto3.client('s3')
def lambda_handler(event, context):
json_data = []
# TZを日本に変更
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime('%Y%m%d%H%M%S')
# 一時的な読み書き用ファイル
tmp_json = '/tmp/test_{ts}.json'.format(ts=timestamp)
for record in event['Records']:
bucket_name = record['s3']['bucket']['name']
key_name = record['s3']['object']['key']
s3_object = s3.get_object(Bucket=bucket_name, Key=key_name)
data = s3_object['Body'].read()
contents = data.decode('utf-8')
try:
# 受信したJSON内容を一時ファイルに書き込み
with open(tmp_json, 'w') as json_data:
json.dump(contents, json_data)
# 上記で作成したJSONファイルロード
with open(tmp_json, 'r') as f:
json_dict = json.load(f)
#辞書型に変換
j = json.loads(json_dict)
# CSVファイル形式の書込
with open(tmp_csv, 'w') as f:
writer = csv.DictWriter(f, fieldnames=fieldnames,
doublequote=True,
quoting=csv.QUOTE_ALL)
# ヘッダ出力する場合はコメントアウトを外す
# writer.writeheader()
writer.writerows(j)
# S3に保存しなおす
with open(tmp_csv, 'r') as csv_file_contents:
response = s3.put_object(Bucket=bucket_name, Key=outputted_csv, Body=csv_file_contents.read())
os.remove(tmp_csv)
os.remove(tmp_json)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
returnJSONL(JSON line形式)
前提条件
JSONL形式を取りこむ際は、外部ライブラリの「pandas」が必要である。
こちらも下記のQiitaを参考に取り込んで頂ければと思う。
本当に、Qiita様々である。ありがとうございます。
Qiita AWS Lambdaでpandasを使いたい!
ファイル形式
JSONライン形式である。
KinesisDataFirehose(配信ストリーム)を介すると、なぜかこの形式で吐き出される。
Athenaで読み込むことを想定しているのかな?
{"type":"device1","date":"2022/07/01 00:00:01","value1":100.001,"value2":29.509}
{"type":"device1","date":"2022/07/01 00:00:02","value1":105.002,"value2":30.001}JSONと似ているが、[]がなかったり、カンマはない。単体のデータを改行で区切ったデータとなる。
ソース
import pandas as pd
import json
import csv
import boto3
import os
from datetime import datetime, timezone, timedelta
s3 = boto3.client('s3')
def lambda_handler(event, context):
json_data = []
# TZを日本に変更
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime('%Y%m%d%H%M%S')
# 欲しいデータ部分のみ取り出す
for record in event['Records']:
bucket_name = record['s3']['bucket']['name']
key_name = record['s3']['object']['key']
s3_object = s3.get_object(Bucket=bucket_name, Key=key_name)
data = s3_object['Body'].read()
contents = data.decode('utf-8')
# print('contents:', contents)
# データフレーム形式に変換
df = pd.read_json(contents, lines=True)
# ファイル名形式を整える
tmp_csv = '/tmp/test_{ts}.csv'.format(ts=timestamp)
outputted_csv = 'output/test_{ts}.csv'.format(ts=timestamp)
# CSVファイル形式で一時ファイルに保存
df.to_csv(tmp_csv, index=False)
try:
# S3に保存
with open(tmp_csv, 'r') as csv_file_contents:
# print('csv_file:', csv_file_contents)
response = s3.put_object(Bucket=bucket_name, Key=outputted_csv, Body=csv_file_contents.read())
os.remove(tmp_csv)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
return動作確認
トリガを設定したS3箇所に、適当なJSONファイルをアップロードすれば良い。
上手く動いている場合は、同じS3のoutputフォルダにCSVファイルが出来上がるハズである。
出来なかった場合は、適宜printを入れるなりして、CloudWatchで調査してみて欲しい。
思うところなど
Python自体が分かっても、Lambdaが理解できない
AWSに実際に触れて、「Lambdaはまんま関数なんでしょ?」って感覚でやる人が多いだろうが、引数に何が入ってくるか分からん! でつまづく人が多いんじゃないかと思っている。
私も上記で紹介したQiitaの記事がなければ一生、分からなかったと思う……。
IoT EventがJSON形式対応
そもそもなんでJSON形式で取り込むの? は、IoT EventがJSON形式にしか対応してないのでが回答となる。
だけど、JSON→CSVは見かけなかったということは……何か根本的に理解してないのか、私?
もっと効率的なインフラ構成があれば是非、ご教授いただけると嬉しい。
GlueでもJSONL→CSV変換は可能
が、少々コストが高い。一日一回ぐらいの頻度じゃないと辛い。
参考までに私が少々やらかした分を参考においておく。
5分ごとにGlue起動×24時間で、$15~$20ぐらいかかったと思う。
Lambdaだと同じ頻度でも10分の1以下になると思う。それぐらい差がある。
Glueでやる場合の記事も見かけなかったので、後で記事にできればしておきたい。
QuickSightはCSV対応
QuickSightはBIツールである。要はデータの見えるかだ。QuickSightのことを考えるとJSONLではなく、CSVの方が扱いやすいかなと思っている。
JSONLのまま、Athenaで一度、取り込めばいいのか? と思わなくもないが……。が、やはり何かと手軽なのはCSVだよなとは思う。何かあってもS3から落とせるワケだし。
QuickSightをやってみると分かるが、そこそこ頻繁にデータセット更新したい人は、S3にCSVファイルを置いた時点で、また一工夫が必要だったりする。
興味ある人は以下のQiitaをどうぞ(ほんと、ありがとうございます)
Qiita 運用が楽なQuickSightダッシュボードを作る_5(データセット自動更新編)
まとめ:AWS沼は深い
が、知れば知るほど、AWSのサービスってかみ合っているんだが、かみ合っていないんだがたまによく分からない時がある。
同じことをやりたくても、方法も幾通りもあるし……どれがベストなのか分からん。
ベストプラクティスは、システム思想にも左右されるのだろうが。むつかしい。
AWSは歴史がそこそこあるからインターネット資料は豊富かと思ってたが、やってみると意外とない。
各言語と違って、google先生に聞いても解決しないことが結構多いなと感じ、筆をとってみた次第である。
これからもちょくちょく書けたらかきたい。


コメント