

S3にあるデータは、Athenaを使うとSQLライクにデータの呼び出しが可能だか、普通に使っていると実はスキャン範囲を指定することができない。
このスキャン範囲を指定するために、データの保管形式を整える(?)ことをパーテーション化と呼ぶようだ。厳密には違うかもしれんが、大体そんなもんだと思ってくれ。
S3にあるデータをパーテーション化した状態で保存するには、Kinesisの動的パーテーション使うと比較的、簡単に行える。今回はその方法と、パーテーション化されたデータをAthenaで検索するまでを紹介する。
本記事でKinesisの使い方は説明しない。Kinesisの根本的な使い方については、以下の記事を参考にしよう。

Kinesisを使って、S3に保存するデータをパーテーション化する
パーテーション化すると言っても、見た目はディレクトリ構造で保存するだけである。
設定例を見た方が理解できると思うので、早速ご紹介する。
まず、動的パーティショニングキーについて、以下のように分割したい単位で作成する。

テキストコピーはこちらから(バックスラッシュがコピペ上手くいかないかもしれないが、画像見て自力で修正してけれ)
| キー名 | JQ式 |
| type | .type |
| year | (.date | capture(“^(?<year>[0-9]{4})[/\\-]”)) | .year |
| month | (.date | capture(“(?<year>[0-9]{4})[/\\-](?<month>[0-9]{2})[/\\-](?<day>[0-9]{2})”)) | .month |
| day | (.date | capture(“(?<year>[0-9]{4})[/\\-](?<month>[0-9]{2})[/\\-](?<day>[0-9]{2})”)) | .day |
| hour | (.date | capture(“(?<year>[0-9]{4})[/\\-](?<month>[0-9]{2})[/\\-](?<day>[0-9]{2})(?<hour>[0-9]{2}):”)) | .hour |
ざっくり説明すると、キー名を受信データからJQ式で生成する感じである。
上記例だと受信データ内にdataのような日時がないと成立しない。
{
"type":"type1",
"date":"2024/05/22 12:00:00",
"value":100
}ちなみに上記例は下記の形式にも対応している(これは私の都合による)
{
"type":"type1",
"date":"2024-05-22 12:00:00",
"value":100
}JQ式は自身が受信するデータに合わせて変更してくれ。
この上で、S3 バケットプレフィックスを以下のように設定する。
xxxxx/!{partitionKeyFromQuery:type}/!{partitionKeyFromQuery:year}/!{partitionKeyFromQuery:month}/!{partitionKeyFromQuery:day}/!{partitionKeyFromQuery:hour}/上記例だと、S3バケット直下に「xxxxx」ディレクトリができ、その下にtypeディレクトリ、それ以下に年月日時ディレクトリの階層ができる感じだ。この辺は増減可能なので、お好きなように改造して良い。
これが正しく動作すると、(私事の都合で一部伏せているが)以下のような感じでS3上に保存される。
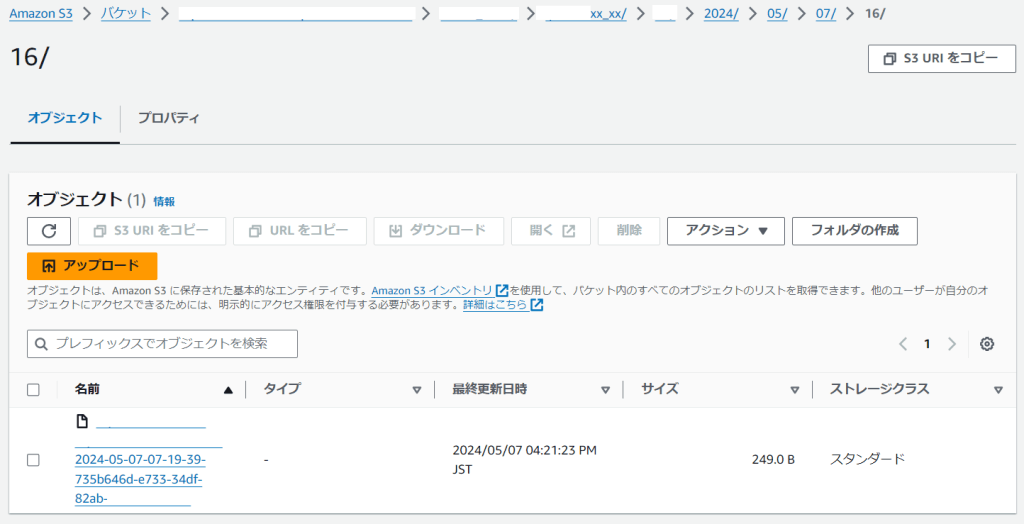
S3でパーテーション化されたデータを、AthenaでSQLライクに読み込む
AthenaでSQLライクにデータを読むにはまず、テーブルを作成する必要がある。
CREATE EXTERNAL TABLE IF NOT EXISTS test-database.test-partition
( type string,
date string,
value int
)
COMMENT 'partition test table'
partitioned by (
year int,
month int,
day int,
hour int
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'ignore.malformed.json' = 'FALSE',
'dots.in.keys' = 'FALSE',
'case.insensitive' = 'TRUE',
'mapping' = 'TRUE'
)
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://{対象のS3バケット名}/partition/'
TBLPROPERTIES (
'classification' = 'json',
'projection.enabled' = 'true',
'projection.year.type' = 'integer',
'projection.year.range' = '2021,2100',
'projection.year.digits' = '4',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.month.digits' = '2',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.day.digits' = '2',
'projection.hour.type' = 'integer',
'projection.hour.range' = '0,24',
'projection.hour.digits' = '2',
'storage.location.template' = 's3://{対象のS3バケット名}/partition/${year}/${month}/${day}/${hour}')ざっくり説明すると、パーテーション化=範囲指定したい部分を「partitioned by」で指定し、想定される範囲等を「projection」で指定する感じだ。長ったらしいが、理解できればそこまで難しいCREATE文ではない。
テーブル作成が出来ると以下のように「パーテーション化済み」と出るハズである。
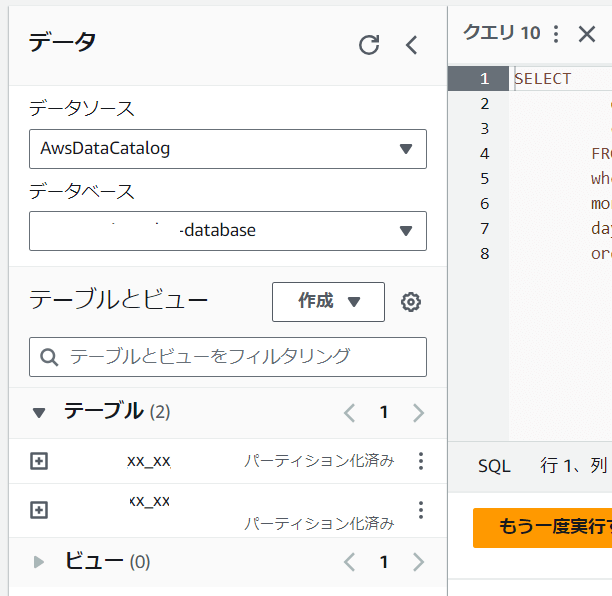
この状態でパーテーション化した部分を、whereで範囲指定してやるとスキャン範囲を絞ることが出来る。
こちらも見た方が理解が早いと思うので、いくつか例を載せておく。
SELECT
date_trunc('hour', date_parse(date, '%Y/%m/%d %H:%i:%s')) AS dt,
type,
value
FROM
"test-database"."test-partition"
where
year = 2024 and month = 5 AND day = 10 AND hour BETWEEN 0 AND 12SELECT
date_trunc('hour', date_parse(date, '%Y/%m/%d %H:%i:%s')) AS dt,
type,
value
FROM
"test-database"."test-partition"
where
year = 2024 and month = 5 AND day = 10 AND (hour = 11 OR hour = 12)SELECT
date_trunc('hour', date_parse(date, '%Y/%m/%d %H:%i:%s')) AS dt,
type,
value
FROM
"test-database"."test-partition"
where
year = 2024 and month = 5 AND day = 10スキャン範囲が本当に絞られているかは、スキャンしたデータで確認できる。whereで条件なしの場合とある場合で、それぞれ確認してみると良い。
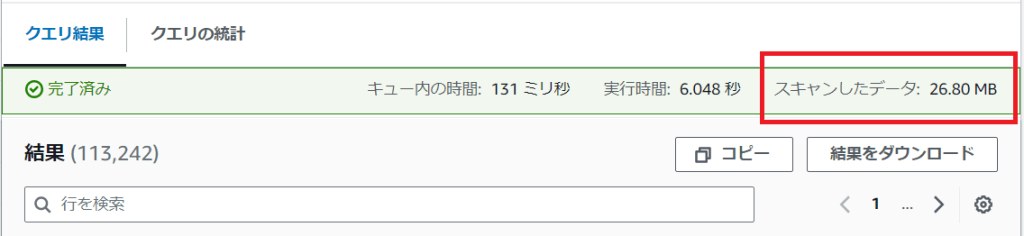
最後に。
現在日時から○日分や○ヶ月分は少し工夫が必要である。
私は以下のようにやっているが、もっとスマートな方法があるなら教えてほすぃ。
SELECT
date_trunc('hour', date_parse(date, '%Y/%m/%d %H:%i:%s')) AS dt,
type,
value
FROM
"test-database"."test-partition"
WHERE
((
year = year(date_add('hour', 9, current_timestamp))
AND month = month(date_add('hour', 9, current_timestamp))
) OR
(
year = year(date_add('month', -1, date_add('hour', 9, current_timestamp)))
AND month = month(date_add('month', -1, date_add('hour', 9, current_timestamp)))
))簡単に説明すると、current_timestampは現在時刻を取得できるのだが、Athena上で実施するとUTC時刻となってしまい、JST時刻ではない。そのため、プラス9時間してから想定する年月日を抽出している状態になっている、と言うワケだ。
そのため、ひじょうに長ったらしくなっているし、やり方として合っているかも分からん。
もう少し何とかなるのだろうか。
蛇足
パーテーションを活用すると、データのスキャン範囲を絞り込めるため、データの呼び出し時間がある程度、一定速度となる。まぁ、そもそもS3へのアクセス自体はそこまで高速ではないため、本当に速度を求めるならDBを使った方が良いのだろうが。
ただ、S3はやはりデータ保管場所として使うには便利なので、あまり速度を求めなくて良いデータは、パーテーション化した上で保存しておき、必要に応じて呼び出す形が良いのだろう。
また、こちらを使っていくと、年月日時の他に「週」単位が欲しくなるが、今のところどうやるのがベストなのか、思いついていない。
誰かベストな方法を見つけたら紹介して欲しい(切実に)


コメント